The growth of the web has come at a cost. Let's rediscover Gopher and Gemini, and discuss the fine line between these protocols, how technology shapes social outcome, and vice versa.
The evolution of the web from documents to applications
The web has evolved significantly, changing from primarily a place to share and reference static documents into a dynamic, interactive, multimedia experience. A lot of what people visit nowadays aren't really "websites" anymore, they are "webapps": applications that just don't need to be installed and are loaded, executed, bit by bit, but with the majority of the processing and storage happening elsewhere.
Along with the rise of web applications came a lot of good, and a lot of bad. It's great that I can sign in anywhere and order groceries to my home. But there's a lot of bad too. Bad like:
- Systemic tracking and monitoring of things that Are None Of Your Business.
- Loss of data ownership, where information is stored in a black box outside your control.
- The growth of software bloat and unnecessary resource usage. The average website size is an abomination.
- Advertising. Everywhere. A completely parasitical proliferation of unnecessary consumerism.
- Security holes such as stealing account details and unwarranted cryptomining.
- The monopolisation of two web engines steering the online capabilities of the world (including other protocols like the email world)
- Loss of accessibility for those with disabilities
- The abuse of free software through using SaaS as a delivery
Note that not all these Bad Things are because of the growth of web applications. You can still have SaaS and social media without a web app, and the the market will probably still exist.
Achieving the modern web involved the development of technologies like HTTP, TLS, CSS, and JavaScript, and the various web APIs. If I had to point at a single culprit that led us down this path, I'd point at JavaScript.
Some of us watched this gradual process occur. HTML started with the ingredients to be a semantic markup language that separated semantics from style (CSS). Slowly, tables were used for layouts. Images were used for text and layout (remember rounded corners?). Embedded applets and blobs were used for entire navigation sections. The term "Div Soup" was coined. Whether you were conscious of it or not, entire page layouts were redesigned to fit "standardised pixel dimensions" of advertisement banners.
Images were warped into the 1x1 tracking pixel. Hotlinking inline resources meant advertising networks could be setup. CSS improvements meant that simple input forms and documents could now look like complex, interactive applications. SSL/TLS meant that sensitive data could be exchanged and opened the doors to the mass commercialisation of the internet.
The mobile internet brought a short renaissance in lightweight browsing, and the "mobile-first design" paradigm, focusing on the most critical pieces of content first. Developers rediscovered the meaning of Progressive Enhancement and the usage of HTML did, for a brief, beautiful moment, shift the needle back towards semantic documents. It wasn't long before that paradigm was replaced with "only available on the app".
Once JavaScript started maturing, things changed completely. HTML denoted
elements that were invisible, and would only appear in certain unknown
circumstances. Or content would be missing completely until unknown triggers
would load them. The <template> tag was the final admission of defeat.
JavaScript, instead of enhancing basic interactivity, became mandatory and
monitored all your behaviour. JavaScript changed the rules on how and when data
was downloaded - it could happen on a timer, in the background, determined by
the application, not by you. JavaScript, used as it is today, has killed the
semantics of the web. Most of the time, we don't look at documents. We execute
real-time software that selectively renders content for us.
Don't believe me? How much JavaScript do you download just to visit a website? Forget downloading HTML, text, images, video, fonts, and so on ... what about just JavaScript on a single page? Here's a list I fact-checked from Tomsky's blog on JavaScript bloat:
- Slack (just after signing in): 55MB
- Jira (fresh empty kanban board page): 50MB
- LinkedIn (home feed): 34MB
- Gmail (inbox) / Ebay (homepage): 18MB
- Instagram / Notion: 16MB
- X / Twitter: 14MB
- Soundcloud / Spotify / YouTube / Facebook / Booking.com: 12MB
- Reddit (viewing subreddit): 10MB
- Github (viewing repo): 8MB
- Bandcamp: 6MB
In contrast, the entirety of 1993's Doom runs in 2.39MB and NetHack 3.4.3 ran in 2MB. That's less than it takes for Google to show a single search input field (2.5MB) on its homepage.
The technology stack also grew in complexity. New programmers were hired who didn't know how to serve a static HTML page. CMSes grew in popularity, causing contented generated from WYSIWYG instead of WYMIWYG. The thickening of the stack centralised hosting and platforms to those sold the dream that they needed the stack.
The stark contrast of websites and web applications caused an imbalance in the social dynamics of the internet. Richer, flashier experiences became preferred outlets, causing a centralisation of activity and content. Accessing remote payloads meant that any website could embed code from other websites for analytics, advertising, embedded social media, and in doing so chained themselves to centralised systems. The utility of user bookmarks started to die out and the walled garden of applications, SEO-optimised content, "lists", "favourites", and "likes" grew. This had a circular effect. Content was now produced not because the content had intrinsic intellectual or artistic value, but instead as a reaction to its "algorithmic performance" on the internet.
From this moment on, there was no turning back. The growing list of web API specifications natively formalised what people were already building. The web had changed.
Gopher, and Gemini, what are they and why do they exist?
The web isn't the only technology out there. Another alternative is one known as Gopher, back in a world where a "URL" didn't really exist as we know it today.
Imagine instead of a web browser visiting a website, you had a file browser visiting a ... uh, a filesite? That's Gopher. Imagine the internet as a big, shared network drive. You browse folders, and inside folders you see a menu listing of files. This file menu may also include some basic explanatory text interspersed within, but not much more. When you open a file, that's it. If you open a text file, you read text. There's no more to it. If someone writes a link inside that text file, you can't click it, since it's just text. You'll copy paste it and manually visit it in your "Gopher browser". No images either. If you want an image, you go back into the folder and open the image separately.
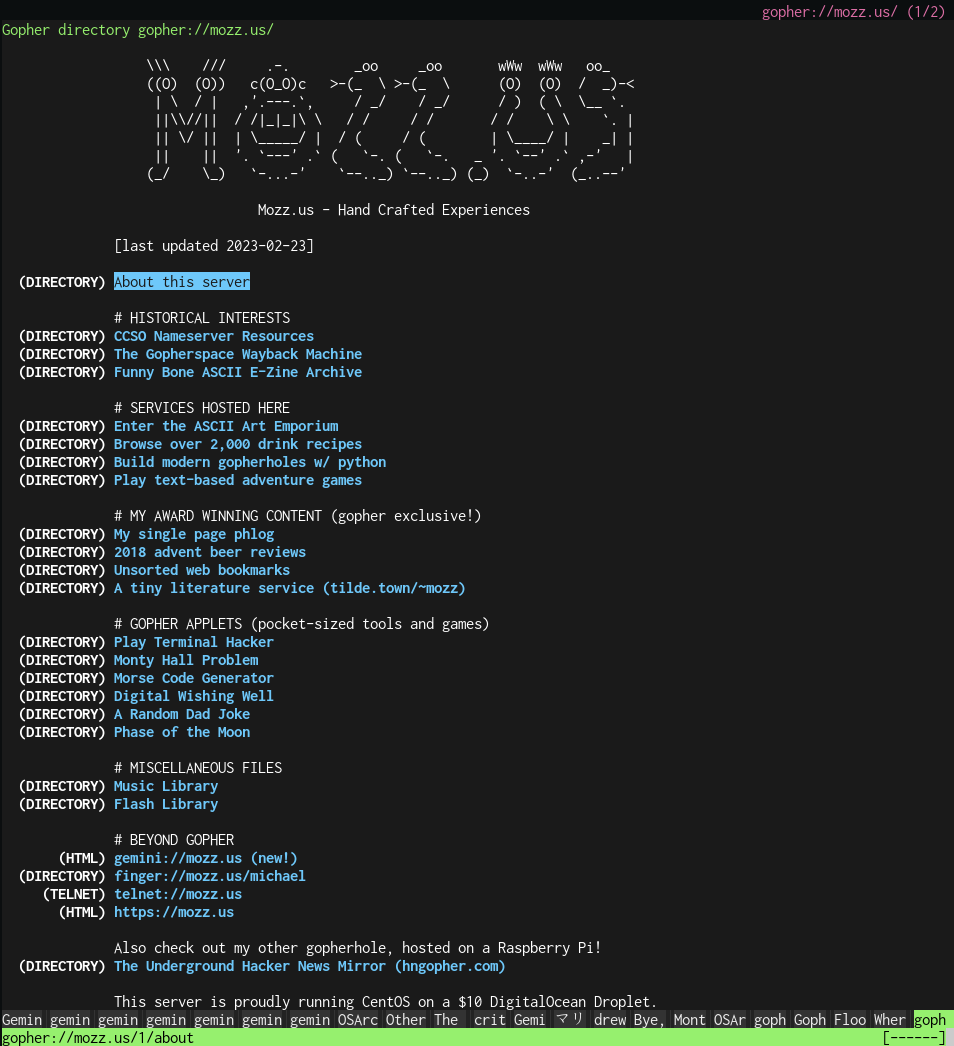
If you want to see for yourself what Gopher looks like without installing a Gopher browser, check out the Floodgap proxy. You'll be visiting one of the hundreds of Gopherholes still online today.
Under the hood, Gopher also lacks many of the technical details that mean it cannot do the same things that our beloved and hated internet can do. E.g. No TLS means no security over financial data, so don't expect to do your shopping on Gopher.
There's an underground society of Gophers currently still active today, but it is a niche of primarily technical folk, preferring a more ascetic digital experience. As a ballpark figure, Gopher has only a few hundred "websites". See the rise and fall of Gopher.
Gopher is inherently different from the web: it distinguishes between menus and files. You navigate through a menu (traditionally hierarchical), and open a (primarily text) file. Meanwhile, the WWW focuses on "documents" with links.
Gemini is a more recent grassroots protocol borne out of Gopherspace, best described as being "somewhere between Gopher and the web". It doesn't have a menu / file binarism but instead adopts the WWW's document-centric approach. However, unlike the mixed-media approach of the web, where a website contains not just HTML, but also images, CSS, and other assets (fonts, JavaScript, etc), a single Gemini document only contains one type of data (e.g. text, or image, but not both).
Gemini, being for a dedicated purpose, was invented alongside a file format known as Gemtext. Gemini + Gemtext is analogous to HTTP + HTML. Gemtext is basically yet another Markdown flavour inclined towards minimalism (i.e. no Markdown tables, no images), with one big restriction: no inline links. Links are distinctly separated from text. If you want a 1x1 tracking pixel image, you have to link to it on its own line. Someone has to explicitly click that link and load that 1x1 pixel image as a separate request. Oh, also no manual line wrapping, line wrapping can only occur on the client side.
Here's what a Gemini capsule (website) looks like. As you see below, it looks mostly the same as any website, except that links are on their own line. In this case, headers are in green, and links are in blue. A Gemini website will look superficially different for different people, depending on their Gemini browser, font, and colour choices.
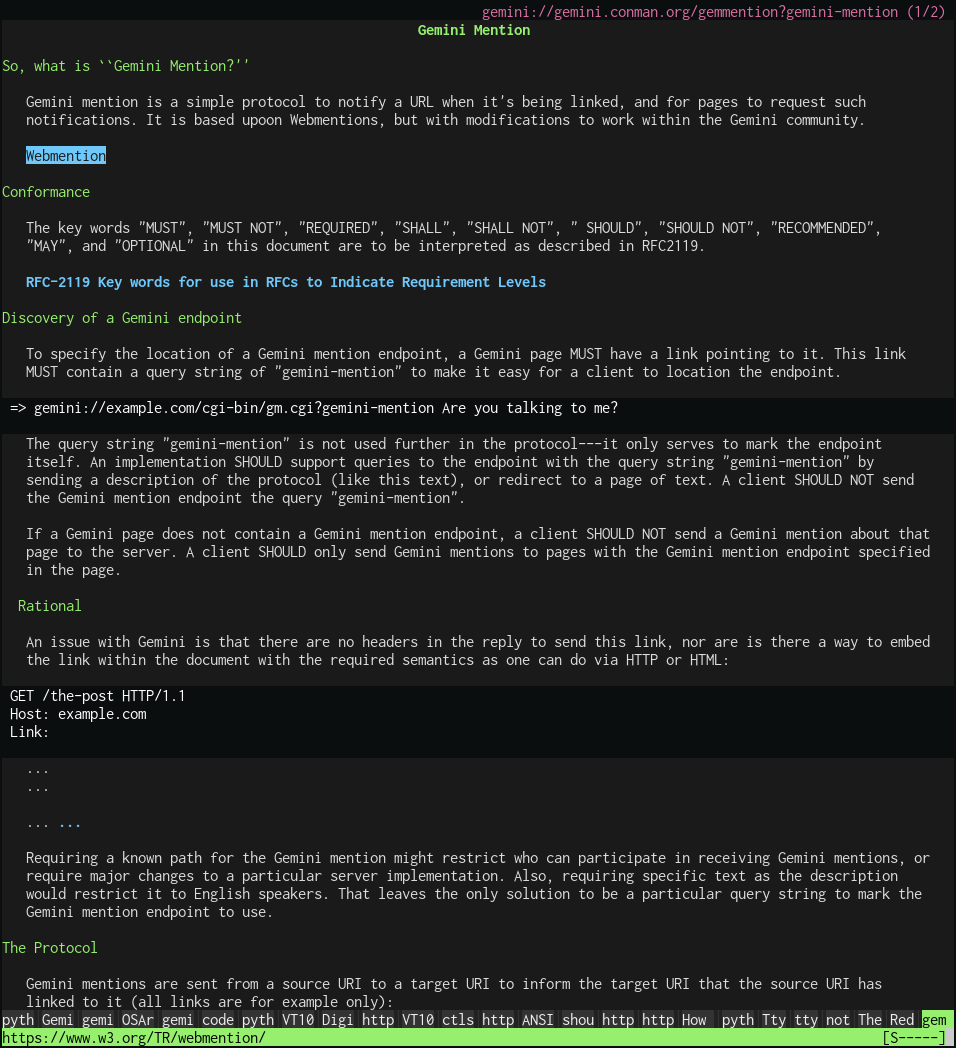
Gemini, in the space of a short few years, have surpassed the number of Gopher websites and now boasts a few thousand capsules (Gemini websites).
Gemini capsules and Gopherholes are very similar. They focus primarily on static text content, with only the occasional image, audio, or video file. The markdown flavour of Gemtext preserves some of the most critical semantic identifiers of the early web (h1, h2, h3, p, ul, pre, a).
If you're curious, visit my Gopherhole and Gemini capsule. It's the same content served across three channels.
All in all, it's a peaceful life.
Why isn't the web like this?
Most websites under the hood already store core, fundamental content in a
separate location. It's a conscious choice by both web developers to present it
in such a cluttered manner. Here's a cute trick on my own website: if you're
using Firefox, press <Alt>. Then in the top menu, go to View > Page Style
and choose Modern. That's right! No JavaScript - just web standards combined
with honest, Brutalist web design.
Let's see how far we can get.
You could get a very similar experience of this simpler time with the web as it is today. If you've read this far, you're on such a website which contains no tracking, semantic HTML, works fantastically on a text browser, no ads, no interactivity, no Javascript, and practically boilerplate CSS. The problem, as identified by the Gemini folks, is that this is voluntary by the server - a reader doesn't know what's going to hit them when they visit a website. Is it going to be a spartan document or a complete software suite?
There's really two separate problems here: the protocol that lends itself to having persistent data about users, and the nightmare trifecta of HTML, CSS, and JavaScript. Put together, this creates the default web engine behaviour which is so ingrained in the culture of being a miniature operating system.
Consider a regular HTTP website that only returned text/markdown instead of
HTML (and imagine we agreed on a dialect). You can configure your browser to
open text and other files (such as gemtext) in the
browser and
then render the contents as
Markdown.
If you'd like you can test it on this article as gemtext. Here's what it can look like:
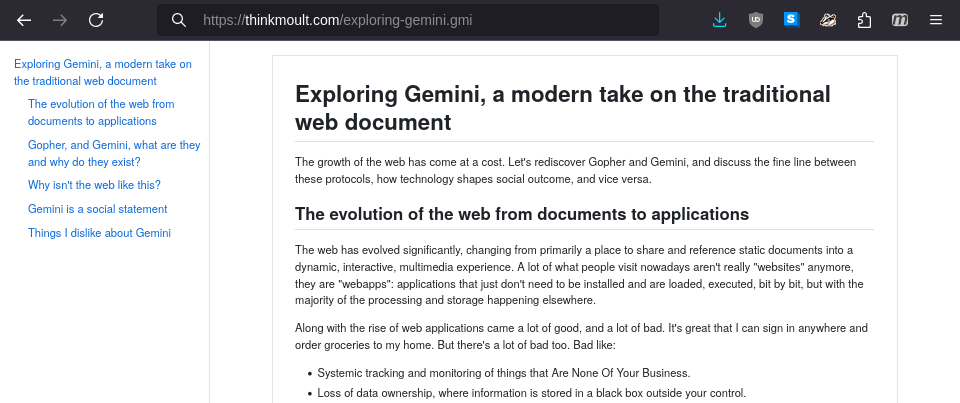
The replacement of the HTML/CSS/JS with spartan Markdown rendering resolves
some issues, such as encouraging semantic text and preventing lawless code
execution on your machine. If servers would return text/markdown instead of
text/html, and browsers rendered it, we'd immediately have a huge distinction
between pure documents and richer experiences.
However, the HTTP protocol still allows for headers, and therefore cookies and
sessions. We'd also need a separate protocol that is similarly spartan,
preserving the ability to fetch data without the persistent bits. HTTP can't
directly be used for this, because we don't know prior to fetching a page
whether or not it needs headers or not (i.e. is a dumb document, or a smart
app). Let's imagine we derived a stripped down version of HTTP, say a
HTTP+GET:// protocol, which is basically HTTP minus RFC6265 (Cookies), minus
any verb that isn't GET, and so on until it preserves just the bits of HTTP
needed to fetch a document and nothing else. Existing browsers would "just
work" with minimal modifications.
This effectively creates two splits. First the protocol: a dumb, privacy respecting document retrieval protocol vs a metadata rich protocol that can continue to evolve for dynamic apps (they're here to stay!). Similarly, we formally standardise (stop inventing Markdown dialects!) rendering a simple, semantic document format, vs a rich, app UI toolkit.
Users can become more aware of the two web worlds: static documents, and dynamic apps. You don't need to rebuild search engines. You don't need to reinvent a BBS. They can coexist.
This minor derivative using existing technologies is effectively a formalisation of what many people already do: use "reader mode" on phones and browsers, use themed "night mode" and overridden CSS, use "no script" and "ad block plus", and get bombarded with "accept cookies"?.
Gemini is a social statement
It seems as though we've already got all the technology we need ... but there's still one problem: it's very difficult to enforce this subset. Non-technical users won't recognise the difference when text/html gets returned from a HTTP+GET:// protocol and still ends up executing JavaScript. Non-technical users will just say "this looks ugly" when text/markdown is return from a HTTP website. Using a subset of the technology would mean that it's hard to draw the line where support starts and stops. What's in it for the two major browser monopolies to support this schism of the web? Are users really going to kick up a fuss if something that "looks" like a document is instead served as an app?
They key message is that although the protocols, servers, and clients can distinguish between the two, psychologically the world of "documents" and "apps" are still conflated.
This is where the strategy like gemini:// as a distinct protocol (i.e. not a
HTTP subset) and the "psychological" coupling of text/gemini to the protocol
come into place. It draws a strict line between the two worlds. This to me is a
trade-off between technical reuse and social manifesto. Although you could
just use the web the way it was used historically, is there a critical mass of
society that feels it is worth inventing a reactionary post-web protocol? Let's
find out.
Note that you can build (basic) apps in Gemini, since nothing stops you putting data in the URL itself. This naturally has a size limitation, so it works for small input fields, search engines, or similar. Gemini is "designed" to be ruthless towards the "gradual feature creep" that formed the modern web, using strategies like not versioning the protocol. Despite this people will still build this stuff because they can. Hopefully because WWW already exists, there won't be much incentive for the same "app creep" to occur.
Things I dislike about Gemini
Daniel Stenberg (the curl guy) makes six technical recommendations which seem very sensible to someone who isn't in the weeds. Meanwhile, I'll stick to commenting on markup.
I think inventing another Markdown flavour is silly. Reuse something more battle tested. Github did a lot of work with their flavour, reuse their work. It's creative commons. I especially dislike the lack of semantic tables.
The reduction of all external media to a "link" is an interesting one. A huge disadvantage is that the semantics of the media type is lost. The alt text and the title text is conflated. At least it does somewhat encourage some title text (even if not alt text) to distinguish between actually meaningful images versus "filler stock image".
The theory is that explicit, separate links encourages intentional resource
loading. But nothing is stopping someone from building a Gemini browser that
fetches all links (including remote ones, such as those much loved tracking
pixels) and renders them inline depending on mimetype. The missing semantics of
the <img> tag discourages indiscriminate "fetching" of these resources, but
doesn't altogether prevent it. Any fetched resource could be used as a tracker.
I'm not convinced text-centricism is the main selling point in 2024. I believe static document centricism should be the goal, which certainly includes a lot of text, but also other media. Non-text media isn't the problem - it's the abuse of unintentional resource loading, and it's the obfuscation of critical document content resources with "layout", "page" or "system" resources. I'd love to have more semantics: images, or "lists of images" (i.e. photo gallery), videos, music, podcasts, spreadsheets, and so on.
I also dislike the loss of document structure semantics. Whilst Markdown
provides basic semantics for a single article, it does not handle multiple
articles, nor navigation. So whilst it handles the "document" portion of
"browsing documents", it's missing on the "browsing" part. A webpage / capsule
still has the semantic concept of HTML's <nav> at the very least, and we
might argue it's useful to have <header> and <footer>. This would allow for
accessible text browsing such as "Skip to Content".
The growth of Gemini
Stats taken from Stéphane Bortzmeyer's capsule:
- 2022: ~1,900 capsules.
- 2023: ~2,500 capsules.
- 2024: ~4,000 capsules.
- 2025: ~4,400 capsules.